This post has moved to http://wishfulcode.com/2010/06/22/managing-code-and-configuration-synchronisation-in-an-iis-web-farm/
When we think about version control, the most common purpose we associate with it is source code.
When we think about maintaining a farm of web servers, the initial problems to focus on solving are:
- Synchronisation – different nodes in the farm should not (unless explicitly told to) have different configuration or serve different content.
- Horizontal Scalability – I want to be able to add as many servers as required, without needing to spend time setting them up or without new builds taking more time to deploy.
- Reliability – no single point of failure (although this has varying levels – inability to run a new deployment is less severe than inability to serve content to users).
Synchronising Content
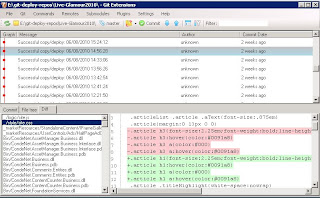
This sounds very similar to the feature set of many Distributed Version Control Systems. Thanks to James Freiwirth's investigation and code (and persistence!), we started with a set of commands in a script that would instruct a folder to fetch the latest revision of a set of files under Git version control and update to that revision. So now we could have multiple servers pulling from a central Git repository on another server and maintaining the same version between themselves. What's more, by using Git the following features are gained:- It's index-based – Git will fetch a revision and store it in its index before applying that revision to the working dir. That means, even on a slow connection, applying changes is very quick – no more half-changed working directory whilst waiting for large files to transfer. FTP, I'm talking to you!
- It's optimised – Git will only fetch change deltas, and it's also very good at detecting repeated content in multiple files.
- It's distributed – All the history of your runtime code folder will be maintained on each server. If you lose the remote source of the repositories, not only will you not lose the data because the entire history is maintained on each node, you will still be able to push, pull, commit and roll-back between the remaining repositories.
Synchronising IIS
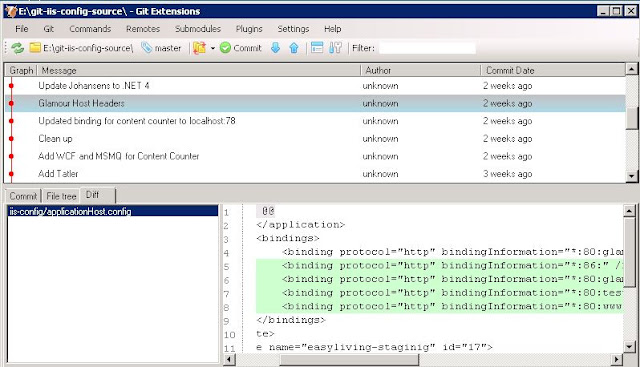
Maintaining web server configuration across all servers is just as important as being able to synchronise content. In the past, options were limited. With IIS7 we gain the ability to store a very semantic and realtime representation of IIS configuration on any file path with the Shared Configuration feature. If we can somehow still store this information locally, but have it synchronised across all the servers then we are satisfying all 3 requirements for synchronisation, scalability and reliability.To accomplish this, we can use the exact same method for synchronising IIS configuration that we use for content. We can set up a git repository, put in the IIS configuration, pull this down to each server and instruct each server's IIS to point to the working copy of the revision control repository. Then, we now have history, comments and rollback ability for IIS configuration. Being able to see each IIS configuration change difference is alone an incredibly invaluable feature for our multi-site environment.
Practical setup (on Amazon EC2)
The final task to accomplish is to identify what process runs on all the servers to keep them always pulling the latest version of both the content and the configuration. The best we've used so far is simple Windows 2008 Task Scheduler powershell scripts, which James gives examples of. However, these scripts themselves can change over time since they need to know which repositories to synchronise. This calls for yet another revision controlled repository. The scheduled tasks on the servers themselves are only running stub files which define a key, to identify which farm, and therefore which sites a server needs, and then runs another powershell script retrieved from a central git repository which ensures the correct content repositories for that farm are created and up to date.The end result is a completely autonomous (for their runtime) set of web servers, which call to central repositories in order to seek updated content and configuration.
If we then create a virtualised image with a Scheduled Task running the stub powershell script, we have the ability at any time to increase the capacity of a server farm simply by starting new servers and pointing the traffic at them. These new servers will each pull in the latest configuration and content.